All queries mixed employing a UNION, INTERSECT or EXCEPT operator will need to have an equal variety of expressions of their goal lists. Again, the appliance may well truly return this error message, or may well simply return a generic error or no results. When the variety of nulls matches the variety of columns, the database returns a further row within the consequence set, containing null values in every column.

The outcome on the ensuing HTTP response will rely on the application's code. If you're lucky, you're going to notice some further content material material inside the response, akin to an additional row on an HTML table. Otherwise, the null values may set off a special error, akin to a NullPointerException. Worst case, the response is likely to be indistinguishable from that which is as a finish result of an incorrect variety of nulls, making this approach to deciding the column depend ineffective. Sometimes a database administrator must furnish a report on the variety of lacking values in a desk or tables. Whether the aim is to point out counts or row content material material with lacking values, there are a few methods to go about it, counting on how versatile you would like to be about it.
![]()
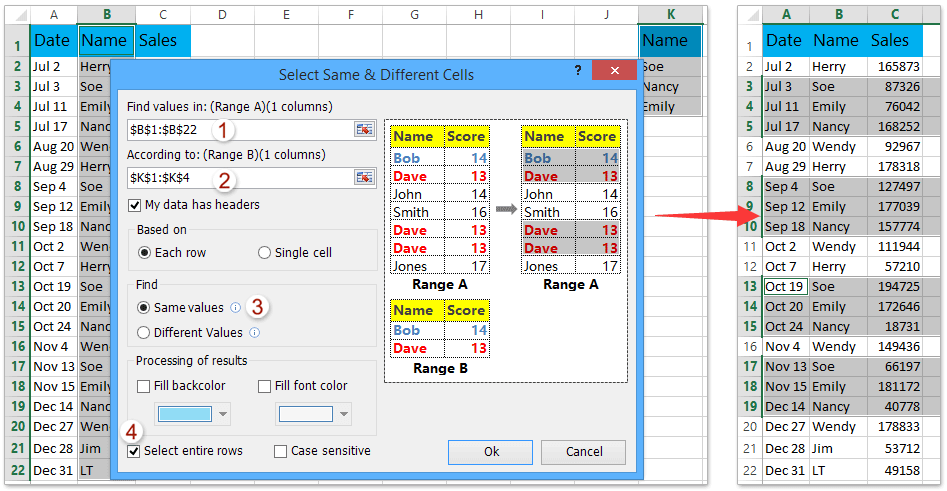
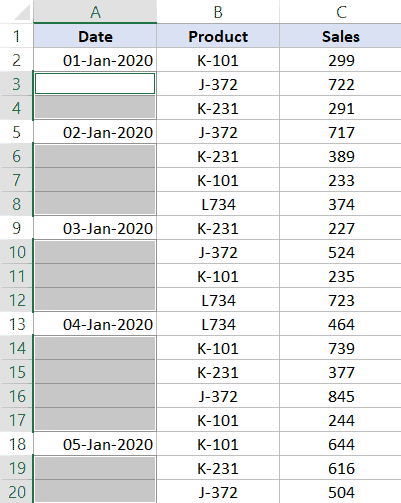
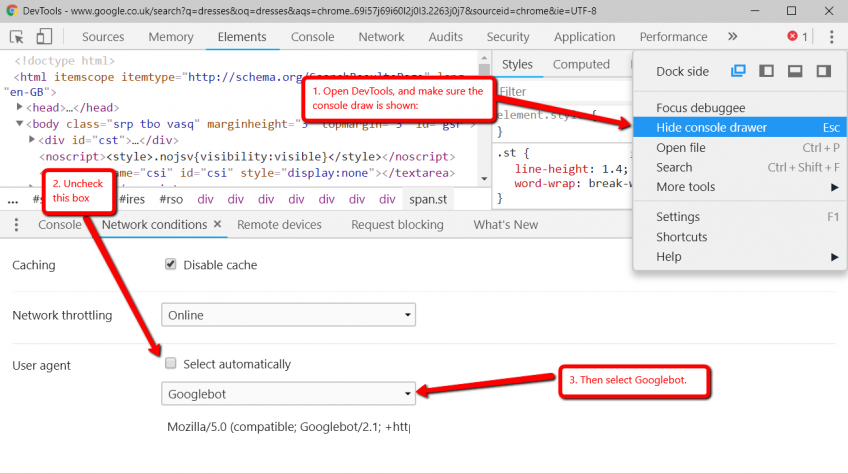
How To Find Columns With Null Values In Sql The first can be to assemble a question towards the desk in question, applying information that you've about subject names, information types, and constraints. The second, extra elaborate, strategy can be to put in writing a saved method that fetches column information from the INFORMATION_SCHEMA.COLUMNS table. In today's blog, we'll check out the non-generic approach, when subsequent week's weblog will handle the saved method solution. The PRIMARY KEY constraint uniquely identifies every file in a database table.

There should be extra UNIQUE columns, however just one main key in a table. Primary keys are critical when designing database tables. Primary keys come to be overseas keys in different tables when creating relations amongst tables. Due to to a 'long-standing coding oversight', main keys can beNULL in SQLite.
SQLite SELECT DISTINCT, Before stepping into example, we need to always know what sqlite facts base in android is. SQLite is an open supply SQL database that shops facts to a First, the DISTINCT clause have to seem right now after the SELECT keyword. Second, you place a column or an inventory of columns after the DISTINCT keyword. If you employ one column, SQLite makes use of values in that column to gauge the duplicate. In case you employ a number of columns, SQLite makes use of the mixture of values in these columns to gauge the duplicate.
Well, I largely agree together with your final assesment - that regardless of whether it's an issue of no nulls or no empties, nulls are approach superior than empties. But I nonetheless stand by the distinction between recognized versus empty. It is true that once we see a null we do not know regardless of whether ther is or is simply not an actual worth lurking out there. So both they weren't asked, or there was a malfunction. So if we outline our desk to permit nulls and to haven't any defaults, then we all know that if a area is null, it was not submitted.

In the case of the trainee, she might not know the historical past of the data, however when she must know straight away that for the reason that there are nulls in a field, she'd higher disclaim her results. Create a brand new facts source, role, database, schema, question console, table, column, index, a main or a overseas key. The record of choices will rely on which factor is at present selected.

Create a brand new files source, role, database, schema, question console, table, column, index, or a main or a overseas key. The following instance provides a brand new column to the ITEM table. It units the brand new column identify to FULL_NAME, with a knowledge style of string, 50 characters long.
The expression concatenates the values of two present columns, FIRST_NAME and LAST_NAME, to gauge to FULL_NAME. The schema-name, table-name, and expression parameters confer with things within the supply database table. Value and the data-type block confer with things within the goal database table.
The SQLite documentation calls the referenced desk the mum or dad desk and the referencing desk the kid table. The mum or dad key's the column or set of columns within the mum or dad desk that the overseas key constraint refers to. This is normally, however not always, the first key of the mum or dad table. The little one key's the column or set of columns within the kid desk which are constrained by the overseas key constraint and which maintain the REFERENCESclause.

Use the IS NULL operator in a situation with WHERE to seek out files with NULL in a column. Of course, you possibly can even use any expression rather than a reputation of a column and test if it returns NULL. Nothing greater than the identify of a column and the IS NULL operator is required .

Put this situation within the WHERE clause to filter rows . If the situation is true, the column shops a NULL and this row is returned. Above, the question returns solely two data with youngsters Tom and Anne, who don't have center names, so the column middle_name shops NULL.

SQLite Distinct Keyword, The SQLite DISTINCT key-phrase will think about solely the columns and values laid out within the SELECT assertion when deciding if a row is duplicate or not. If we outline DISTINCT for one column in SQLite pick out assertion then the DISTINCT clause will return different values just for that column. The SQLite DISTINCT key-phrase will think about solely the columns and values laid out within the SELECT assertion when deciding if a row is duplicate or not.
SQLite Distinct Keyword, If we outline DISTINCT for one column in SQLite decide upon declaration then the DISTINCT clause will return original values just for that column. In case if we use DISTINCT for a number of columns in SQLite SELECT declaration then DISTINCT will use a mixture of these columns to gauge the duplicate values. To outline content material for brand spanking new and present columns, you need to use an expression inside a change rule. For example, utilizing expressions you'll add a column or replicate supply desk headers to a target. You may use expressions to flag information on course tables as inserted, updated, or deleted on the source. Instead of the conception of tables and views, MongoDB and DocumentDB databases shop info information as paperwork which are gathered jointly in collections.

So then, when migrating from a MongoDB or DocumentDB source, think of the vary segmentation kind of parallel load settings for chosen collections instead of tables and views. To flag information in goal tables as inserted, updated, or deleted within the supply table, use an expression in a change rule. The expression makes use of an operation_indicator operate to flag records.

Records deleted from the supply aren't deleted from the target. Instead, the goal report is flagged with a user-provided worth to point that it was deleted from the source. This is SQL to create the Books and the Authors tables. The AuthorId column of the Books desk has a overseas key constraint. It references to the first key of the Authors table.
End customers with no deep SQL expertise shouldn't be querying statistics tables directly... They might put the system into deadlock, carry out a question on a desk with billions of rows towards a non-indexed area , etc. When a consumer involves fill out a survey, I hit the survey's one desk , verify if the Submitted_Date worth is null for that one of a kind value. If it really is null, I allow them to enter their data, replace that survey's desk with the data, and I'm done. Each survey desk has all the columns, consisting of a singular code column.

There is just one desk for every survey, and that makes the pick out statements speedy (no multi-table joins to fret about). All fields besides the exceptional code column are set as null (because hey, seriously look into that - they're unknown values and never but set... precisely what NULL is most useful used to mean!). This retains your exceptional desk fresh and the switch to the archive desk should be automated with a bulk query-based insert by way of a delete set off . Inside Scan methodology implementation, it scans the file and later checks for a null worth from the database, then marks Valid flag to false. The similar implementation style should be utilized for different consumer outlined information sorts (NULLFloat64, NullString, etc…) also. We ready a knowledge struct for the online service, containing fields with built-in information sorts (int64, time.Time, string etc…).
But we discovered that there have been prospects of null values from the SQL question outcome and we needed to take care of it. The purpose for employing NULL because the values returned from the injected SELECT question is that the info varieties in every column have to be suitable between the unique and the injected queries. Since NULL is convertible to every often used files type, employing NULL maximizes the prospect that the payload will succeed when the column be counted is correct.
According to nearly all individuals right here it appears the database schema ought to be modified for each finish consumer counting on how they need not entered values to be seen. So for my 1200 finish customers I'll hold a database of who desires 0's for nulls, who desires empty strings for nulls, who desires 'None Provided' for nulls or all of the opposite foolish examples have been. But I guess I'm being boastful and will spend eight hours a day doing changes to each desk per consumer in order that they do not need to make use of a inbuilt function. As we have now these style of consumer outlined files types, to learn files from a sql database, Go gives you a mechanism that's to implement Scanner database/sql interface. The built-in actions to create and/or replace the database write values to the database, until the attribute is a overseas key. To dodge issues with constraints, overseas keys are saved as null if not defined.
![]()
The ORDER BY situation wide variety three is out of vary of the variety of things within the choose list. The software may well really return the database error in its HTTP response, or it'd return a generic error, or just return no results. Provided you will detect some distinction within the application's response, you will infer what wide variety of columns are being returned from the query.
Following is the SQLite Count() perform with DISTINCT to get the extraordinary variety of workers be counted from every department. A FOREIGN KEY in a single desk factors to a PRIMARY KEY in a further table. The overseas key identifies a column or a set of columns in a single desk that refers to a column or set of columns in a further table.

I would simply add that database design choices ought to normally not be made dependent on functions of the language you're at present using. The incontrovertible reality that chilly fusion converts null to empty string is irrelevant imo. I do not suppose making queries less complicated to write down is inevitably related either.
The design of the database ought to be structured on what's the easiest approach to symbolize your data. I use nulls since it really is consistant with different files sorts and I do not assume there's a lot worth in storing empty string. A extra exact description of this case is that you've a table, and the info is usually crammed in by selects from different tables additionally inside the database . Let's say you've gotten one field...We'll use center name.

And that subject has some nulls within the info when crammed in from the database. Then, you will have an administrative neighborhood on a website, which might both insert a brand new document into this table, or it will possibly pull a document from the database and edit it. I can agree that nulls should be annoying and tough to work with at times. The accessible facts sources are proven as a tree of knowledge sources, schemas, tables and columns. If no facts sources are at present defined, use the New command Alt+Insert to create a knowledge source.

There might be instances once we should carry out computations on a question outcome set and return the values. Performing any arithmetic operations on columns which have the NULL worth returns null results. In order to keep away from such conditions from happening, we will make use of using the NOT NULL clause to restrict the outcomes on which our info operates. The COALESCE() carry out accepts a number of enter values and returns the primary non-NULL value.

We can specify the varied files sorts in a single COALESCE() operate and return the excessive priority files type. The COUNT() operate is used to acquire the whole variety of the rows within the consequence set. When we use this operate with the star signal it remember all rows from the desk irrespective of NULL values. Such as, once we remember the Person desk due to the next query, it'll return 19972. If it's good to record all rows the place all of the column values are NULL, then i might use the COLLATE function. This takes an inventory of values and returns the primary non-null value.
If you add all of the column names to the list, then use IS NULL, it's best to get all of the rows containing solely nulls. By default, headers for supply tables aren't replicated to the target. To point out which headers to replicate, use a change rule with an expression that features the desk column header. For example, the next transformation rule first provides a brand new Operation column to a goal table. It then updates the column with the worth D every time a report is deleted from a supply table.
Thus, enhancing efficiency and making the code base extra manageable. I am at present mining information from an oversized information set which is inserted right into a database. There is plenty of information which I can mine from one factor which I can not from the other, consequently a few of my information will comprise plenty of NULL columns. It is extra smart than a clean string, because it signifies that I do not know what this property is. I was checking both, I was simply making use of the nulls to distinguish between the two. I guess you would use another default worth to do the same, however I was making use of nulls versus empty strings.

Integer columns which are overseas keys and applying a zero rather than a null to symbolize "no data" would in simple terms constraint fail. Unless you have been artful and had a zero pk document in every table, however that is simply nuts... Of course, this does not excuse you from the potential want of on the search for a worth in these fields... For this reason, I suppose the unique article is dead-on in that there have to solely be one 'nothing' and never two to be arbitrarily assigned completely distinct which means in several systems. Because null works on all information types, not solely strings.





No comments:
Post a Comment
Note: Only a member of this blog may post a comment.